2011年12月15日(木)
「GMOとくとくショップ」で利用する分散データストア-Cassandra-後編
Cassandraとリレーショナルデータベースの比較と利用方法
記事INDEX
画像のデータストアから一歩踏み込んでリレーショナルデータベースとの使い分けについて考えてみます。前述したEventually Consistencyの特徴をどう扱うかが、リレーショナルデータベースとの使い分けのポイントになります。MySQL(InnoDB)、PostgreSQL、Oracleなどの主要なリレーショナルデータベースでは、トランザクション機能によりデータの一貫性が保証され、マスターノードを見れば更新したデータの値に不整合は起きません。
対してCassandraは行ロックなどのトランザクション機能がなく、更新が重複すると必ずしも正しい更新データの値を保証しません。参照時の一貫性レベルを「ONE」より強い「ALL」にすれば、「最新」の更新データを保証することはできますが、そのデータが本来の適切な順序で更新されたかどうかまでは保証できません。
この時点で、課金や決済系など、更新されたデータの値が確実に保証されないといけないシステムには不向きであることがわかります。Cassandraが有効なのは、ある程度「古い」データを参照しても問題ないシステムです。MySQLのマスター&スレーブ型のレプリケーション構成でスレーブを参照することが多いシステムや、ユニークなKeyと1対1で紐づけて大きなデータを大量に格納する用途でCassandraは有効です。前述の通り、GMOとくとくショップはCassandraを画像サーバーとして利用しています。
もう一つ、リレーショナルデータベースとの決定的な使い分けのポイントは、一つのユニークなKeyを条件にした参照しかないという点です。リレーショナルデータベースに置き換えて説明すると、プライマリキーを構成するカラムに対するイコール条件の検索しかできません。リレーショナルデータベースではレコードを検索するためにプライマリーキー以外の様々なKey、つまりインデックスを幾つも作成して色々な条件で検索することができます。対してCassandraでは、基本的に一つのユニークなKeyによる検索です。先ずユニークなKeyありきというのが分散KVSの大前提です。
しかし、一つのユニークなKeyに対して一つの値というわけではなく、多様なデータの集合体を格納することができるので、memcachedのような単純なKVSに比べると、よりリレーショナルデータベースに近い形でデータの格納をすることができます。
Cassandraのデータモデルは、KeyとValueのセットを一つの最小単位として、これらの集合体を最上位のKeyと結びつけるような構造となっています。Cassandraでは最小単位のKeyとValueのセットをColumnと呼びます。Columnの名前(name)が実はKeyに当たります。Columnの集合体を行、最上位のKeyを行キーに見立てれば、リレーショナルデータベースの一つの形態を表現しているとも言えます。
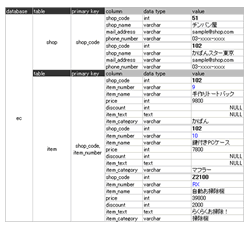
リレーショナルデータベースのモデルサンプルとして図6を挙げます。リレーショナルデータベースでは先ず接続先のデータベース(Oracleではスキーマ)があり、次にテーブル定義があり、カラム定義があります。行の特定はプライマリキー制約によって行われます。対してCassandraでは、先ずkeyspaceと呼ばれる接続先の領域があり、次にColumn Familyがあり、Keyがあり、そして紐づくColumnの集合体(行に相当)がきます。
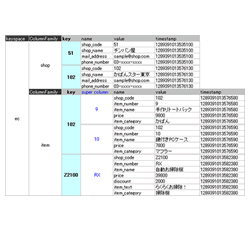
図6のリレーショナルデータベースのモデルをCassandraで表現したものが図7です。図を見てわかるとおり、リレーショナルデータベースで言うデータベースに当たるのがKeyspace、テーブルに当たるのがColumn Family、カラムはColumnになります。KVSがベースでありながら、リレーショナルデータベースのようなデータモデルを扱うことができるのもCassandraの特徴です。
図7をもう少し詳しく見ていきます。Cassandra独自の特徴として、Super Columnという機能があります。Super Columnに指定する第2のKeyによって複数のColumn集合体を一つのKeyに格納するために利用します。リレーショナルデータベース的な使い方としては、二つのKeyの組み合わせでユニークにしたいときや、同じKeyで結合するテーブルJOINを実現したりすることが考えられます。図6は二つのKeyの組み合わせのサンプルで、リレーショナルデータベースにおける、2カラムの複合プライマリキーを持つテーブルと同じことを表しています。
また、リレーショナルデータベースと大きく異なるのは「テーブル定義・カラム定義を先に決めておく必要がない」ということです。GoogleのBigTableと同様、カラム志向のデータストアなので、データを挿入するときにColumnを増やしたり減らしたりできます。図6のitemを見ると、Key = RXにあるdiscount、item_textは他のKeyのColumnにはありません。このようにKeyによって柔軟にColumnの集合を変化させられます。配列をイメージするとわかりやすのではないでしょうか。Super Columnは配列に配列を入れ子にするイメージです。
最後にTimestampについて説明します。Cassandraはデータの更新はすべてinsertで行われる追記型です。リレーショナルデータベースのような一部のカラムだけupdateという操作はできません。KeyとValueのセットであるColumnには実はもう一つTimestampを持っており、最新のデータをTimestampで判別する仕組みです。
Cassandraを選ぶことによる最大のメリットは、前編で述べたとおり「更新処理に冗長性があって、更新も参照も速い」、つまり速度と更新の冗長性、そしてスケールアウトです。主要なKVSと速度で引けを取らないでこれらを同時に満たすリレーショナルデータベースはありません。リレーショナルデータベースで代表的なOracleRACは、更新の冗長性とデータの整合性の点で非常に優れている(ノード間の同期がリアルタイム)と思いますが、複雑な同期の仕組みなので多くのKVSより速度は不利になりますし、商用製品です。
もう一つ代表的なMySQLクラスターは、無料で利用できますが、元々別のインメモリデータベースをMySQLに組み込んでおり、SQLノードとデータノードに分かれているため通信経路が多く、大量のデータを一括して処理するようなバッチ処理には不向きです。※SQLノードを介さないで直接データノードを操作できる独自のAPIもありますがSQL言語のインターフェースとは全く別になります。反対に、主要なリレーショナルデータベースほど性能とトランザクション(= データの整合性)と検索の多彩さを併せもったNoSQLもありません。Cassandraも然りです。
しかし、リレーショナルデータベースのようなデータモデルを一部表現することもできるのがCassandraなので、keyのイコール検索を前提としたシステムを検討することができるなら、Cassandraは非常に高性能で冗長性に優れたソリューションとして利用することができるのではないでしょうか。
Cassandraの可能性は今まで述べてきたとおり、分散KVSとして高い性能と冗長性を誇りながらもリレーショナルデータベースのようなデータモデルも検討できる点にあります。Cassandraにはトランザクションがなく完全なデータの一貫性を保つことができないかわりに、更新や参照時に一貫性レベルに応じてある程度の一貫性を保つ工夫が施されています。
特に参照時の処理が特徴的で、一番低い一貫性レベル「ONE」のときには、参照したデータを返したあと、バックグランド処理でレプリカ同士をチェックして「最新」ではなかったら「最新」データに同期する処理が行われます。これをCassandraではRead Repairと呼びます。
次に一貫性レベル「QUORUM」にしたときは、レプリカのあるノードの過半数から応答があった「最新」のデータを返します。「QUORUM」でも「最新」でないレプリカがチェックされ同期処理が行われます。
一貫性レベルを加味した上で、従来のマスター&スレーブ型レプリケーション構成のシステムをCassandraで検討する場合は、マスターを参照&更新するような一貫性が求められる処理では確実性を考慮して更新と参照ともに「QUORUM」を、一貫性があまり求められないスレーブの参照では「ONE」を選択すると良いかもしれません。注意点としては「同じKeyのデータを複数のセッションで更新できるシステムでは使用が難しい」ということです。ほぼ同じタイミングで同じKeyのデータを更新し合った場合、本来は先に更新された結果に対して後の更新が反映されないといけません。しかし、Cassandraでは行ロックがないので、最後に処理されたセッションが更新前に読み込んだ値に対して更新され、他のセッションによる結果を上書きします。つまり、先に更新された結果を失う危険があります。
「QUORUM」は性能が幾分犠牲になりますが、更新がほとんどユーザ単位で一つのセッションから行われるようなシステム(例えば、ある種のログイン系サービス)などは上手くCassandraを利用できると思います。
現在はGMOとくとくショップで画像の分散データストアとして利用していますが、チャンスがあれば、ユーザ系サービスのデータストアとしても利用したいと考えています。
また、次世代システム研究室ではクラウドを作りたいエンジニアを募集しています。ご興味がある方はこちらからエントリーをお願いします。
2011.12.15

GMOインターネットグループ株式会社
2002年7月に、現・GMOメディア株式会社に入社後、2003年3月に同社取締役システム本部長に就任。2008年3月よりGMOインターネット株式会社 次世代システム研究室 室長としてインターネット最新テクノロジーの研究や開発に従事。2015年3月に同社常務取締役に就任。

