技術ブログ
2015年7月29日(水)
インターネット調査のサンプリング技術と今後の展望-Vol.1
定量調査における標本抽出の概念とその重要性
第一回は、定量調査における標本抽出の概念とその重要性、加えて標本抽出手法の変遷についてレポートいたします。
記事INDEX
■定量調査と定性調査
一般的にリサーチは、定量調査と定性調査の2つに大きく分けられます。このうち定量調査では通常アンケート調査が行われ、「1,000人中60%が満足しました」など明確な数値結果が示されます。一方、インタビューに代表される定性調査は、「多くの人がこうした意見を強く示しました」などの言葉や画像といった質的データが結果として提示されます。
■定量調査における標本抽出
定量調査において、調査対象全体の集合体を母集団と呼びます。たとえば、1万人の母集団の傾向を調査しようとすれば、本来なら1万人にアンケート調査を行って集計するのが、最も誤差が発生しない方法(全数調査/悉皆調査)(※1)です。しかし、母集団全員に対する調査は大変な時間と手間、費用がかかるため現実的ではありません。そこで一般的には母集団から標本を抽出(サンプリング)して調査を行います。このとき大事なのは、抽出した500人や1,000人などの標本が母集団の縮図となっていることです。このように標本抽出に関する誤差(※2)を一定範囲内に抑えつつ、抽出した標本から母集団を推定できる「標本調査」は、調査コストや調査期間を大幅に圧縮できる点でも優位性を持っています。(図1)
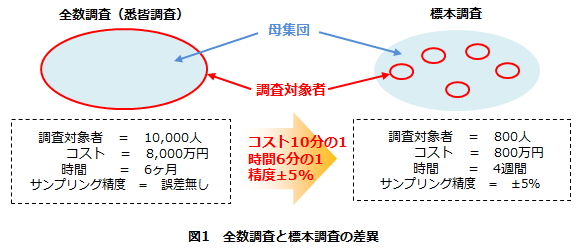
(※1)全数調査(悉皆調査)は、母集団全員に対して調査を実施するため、そもそもサンプリングという操作が必要ない。したがってサンプリングに関する誤差(カバレッジ誤差、標本誤差)は発生しないが、調査実施段階での誤差は発生する可能性がある。それは、すべての回答が得られないことに起因する無回答誤差や調査員の不適切なオペレーション、調査対象者の誤解、調査票の不備等に起因する測定誤差などである。カバレッジ誤差および標本誤差については、本記事の「2.無作為抽出法の手順と誤差」を参照。
(※2)標本調査の場合は、誤差をまったく含まない値(真の値)であるのに対し、調査実施段階での誤差に加えて、全数調査では発生しないサンプリングに関する誤差(カバレッジ誤差、標本誤差)が発生する可能性がある。ただし、適切なコントロールによって、これらの誤差を推定したり、一定範囲内に抑えたりすることが可能である。
■標本抽出の手法
定量調査の結果の蓋然性(結果の確かさ)を支えるのは、母集団から標本(調査に参加する調査対象者)を抽出するための理論に基づいた手法になります。こうした標本抽出の手法には有意抽出法と無作為抽出法(ランダム・サンプリング)の2つがあります。前者は主観的に母集団を代表すると考えられる標本を抽出する手法で、後者は主観的判断を排除して統計的に母集団を代表する標本を抽出する手法です。たとえば高級ブランド品の調査など、対象者を絞った方がより精度の高い結果が得られると判断したときは有意抽出法が用いられるケースがありますが、一般的には調査結果の統計的評価が可能で、人間の先入観に左右されない無作為抽出法が多く用いられています。次に無作為抽出法を用いた標本抽出の重要性について述べたいと思います。
■標本抽出の重要性
そもそも標本抽出の重要性が認識されるようになったのは、1936年のアメリカ大統領選挙がきっかけと言われています。この選挙は現職のフランクリン・ルーズベルト候補(民主党)とアルフレッド・ランドン候補(共和党)によって争われました。週刊誌リテラリー・ダイジェスト(The Literary Digest)社は郵送調査で230?240万票の回収を得てランドン候補圧勝という予測をしました。リテラリー・ダイジェスト社は1916年以降の大統領選挙を同様の手法で正確に予測していて、今回もランドン候補の勝利は間違いないと思われていました。そうした中、前年に設立されたアメリカ世論研究所(現在のギャラップ社)は5万票のサンプルから、逆にルーズベルト候補の大勝利を予測しました(※3)。結果的にはルーズベルト候補が大差で再選され、その後ギャラップ社は大躍進を遂げることになります。なぜリテラリー・ダイジェスト社の予想は外れたのでしょうか?実は、同社が回収したサンプルは自社の雑誌購読者や自動車・電話の保有リストが母体となっていました。これらの人々は当時の世界大恐慌下でも雑誌を購読し、高額の自動車・電話を保有していることから所得の高い社会階層だということが分かると思います。こうした層は共和党支持者が多く、アメリカ全体の有権者の動向を反映していなかったのです。
一方、アメリカ世論研究所は、統計的な手法に基づいてアメリカ国民全体を代表する標本抽出を行ったため、正しい予測をすることができました。このことから、定量調査の正確さを担保するには、単に標本数の大きさを追求するのではなく、統計学的な観点から母集団の特性を代表する標本を抽出することの方が重要だと広く認知されるようになりました。
マーケティング・リサーチも同様で、調査対象の製品が市場で受け入られるかどうかを事前に調査するのが主な目的になります。その際、調査対象者(標本)が製品のターゲットである母集団の縮図になっていないと物事を正しく判断したり、予測したりできなくなってしまいます。そのため標本の代表性を統計学的に証明できる無作為抽出法はマーケティング・リサーチにおける重要な手法とされてきたのです。
(※3)以下参照
http://en.wikipedia.org/wiki/The_Literary_Digest
http://en.wikipedia.org/wiki/Opinion_poll#History_of_opinion_polls
■典型的な手順
無作為抽出法には多くの手法がありますが、「作成した標本が母集団の人口構成に比例し、統計学上の誤差に収まっていること」「一切の人的作為が排除されていること」という2つの条件が担保されることによって、「母集団を構成する各標本が調査対象として選ばれる確率が等しくなっていること」が基本的なルールです。典型的な抽出法は次の通りで、単純無作為抽出と呼ばれています。
①母集団を構成する全標本のリスト(標本抽出枠)を準備する。わが国では、住民基本台帳や選挙人名簿が長い間使用されてきた。
②リストを構成する全標本に対して、通し番号を付与する。
③乱数表や作為の入り込まない数列を用いて必要な標本数を抽出する。(ex.先頭の人をクジや乱数表を使って選んだ後、リスト中から100人ごとの等間隔で抽出する等)
■層化と多段抽出
上記の単純無作為抽出を基本としながらも実際の定量調査では層化や多段抽出と呼ばれる操作が施されることが多いです。
・層化
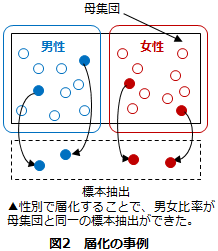
母集団がいくつかの異なる集団(グループ)によって形成されているとき、事前にそれらの集団を分割(層化)し、母集団とその集団が同じ割合になるように標本を抽出していく手法で、性・年代・地域などの属性がよく用いられます(図2)。調査対象項目に性別が強い影響を与えることが経験的に分かっている場合は性別を層化することにより、単純無作為抽出によって生じる可能性のある誤差を補正できるため、精度を向上できます。
・多段抽出
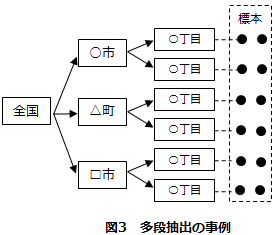
母集団から直接無作為抽出を行うのではなく、いくつかの集団を抽出し、その集団の全数調査を行ったり、その集団から標本を抽出したりする手法です。たとえば日本全国を対象として訪問面接調査を実施する場合、単純無作為抽出を行うと、日本全国に標本が分散して調査コストが膨大になります。そこで、まず市町村を抽出(この段階で層化することが多い)した後、たとえば一丁目だけを標本として抽出することで調査員の移動距離を短縮し、コストを抑えることができます(図3)。
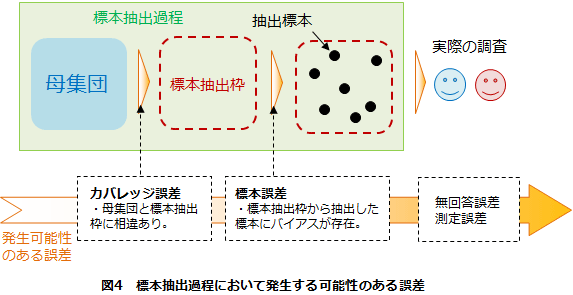
■誤差
標本抽出過程でサンプリングに問題があって生じる誤差には、主としてカバレッジ誤差と標本誤差(図4)があります。こうした誤差の発生をコントロールすることは、定量調査設計の重要な要素となっています。なお、調査の実施状況によっては無回答誤差、測定誤差といった誤差が、調査の実施段階で生じる可能性がありますが、サンプリングの問題ではないため、ここでは取り上げません。
・カバレッジ誤差
標本抽出は母集団を構成する全標本のリスト(標本抽出枠)を基に行い、標本抽出枠と母集団にズレがある際に発生する誤差をカバレッジ誤差と呼んでいます。
たとえば、日本国民全体の意識調査を実施するとき、標本抽出枠として住民基本台帳を用いていたのですが、2012年までは在日外国人が含まれていませんでした(※4)。この場合、「日本国民全体」という定義に在日外国人を含んでいると考えれば、調査設計と実際の調査対象者に誤差が生じることになります。また、同様に電話帳を標本抽出枠として用いると、電話帳に番号の掲載していない人やそもそも固定電話を持たない人が調査対象に含まれなくなります。このような事態を避けるため、標本抽出枠の設定時には母集団と一致しているかどうかを確認する必要があります。
(※4)2012年7月に外国人登録法が廃止されるとともに住民基本台帳法が一部改正され、外国人住民についても住民基本台帳の適用対象に加えられたため、現在では外国人住民の住民基本台帳が作成されている。
・標本誤差
決定した標本抽出枠から無作為に抽出していくと理論的には母集団を代表する標本になると言われていますが、20代や無職者が多数を占めるなどの偏った結果になる可能性はごくわずかながらあります。このように母集団と抽出標本の間に生じる誤差を標本誤差と呼び、中には代表性を失ってしまうほどの誤差が生じることもあります。これらを防ぐためには前述した層化などを行うことが有効だとされています。また、無作為抽出法であれば、この誤差を統計的に算出することも可能です。
長年にわたって定量調査は標本抽出の理論を基に実施することで、その代表性を担保してきました。しかし、標本抽出理論の根幹を支えてきた無作為抽出の実施は、わが国では1990年代頃から困難になっています。それにともなって、近年行われるようになった定量的なマーケティング・リサーチは非確率的な手法が主流になっています。
■標本抽出枠の利用が困難に
最大の要因は標本抽出枠として利用されてきた、リスト(住民基本台帳、選挙人名簿、電話帳など)の利用が困難になったことです(表1)。
1967年に設けられた住民基本台帳は、もともと公開が原則でした。しかし、個人情報保護意識の高まりの中で、1990年代になると自治体がマーケティング・リサーチ目的での閲覧申請を拒否する事例が表れるようになりました。最終的に2005年4月の個人情報保護法施行で、公的な目的以外での閲覧は原則禁止となっています。
電話帳についても掲載率の大幅低下に加えて、携帯電話の普及に伴う固定電話契約が減少したことで、標本抽出枠としての意味を失いました。
(※5)総務省「住民基本台帳の閲覧制度等のあり方に関する検討会報告書」(2005年)によると、2004年度の住民基本台帳閲覧請求件数1,508,799件のうち、請求事由別で「ダイレクトメールその他の営業活動」が69.9%を占めていた。
| リスト | 変化した内容 |
|---|---|
| 住民基本台帳 | ■閲覧申請時に目的の明記が必要となり、自治体が不当な目的を拒否できるようになった(1986年6月) ■住民基本台帳ネットワーク稼動に伴って住民票の記載を氏名、生年月日、性別、住所の4項目に制限(2002年8月) ■熊本市で全国初の住民基本台帳閲覧制限条例施行(2004年8月) ■台帳閲覧制度を原則公開から原則非公開に見直し(2006年11月) 調査に関しては「統計調査・世論調査・学術研究等の調査研究のうち、公益性が高いと認められるものの対象者を抽出する目的で閲覧する場合」以外は認められなくなった。また、成果物の確認、収集情報の廃棄手続書類の提出等が求められ、罰則規定も導入された。 |
| 選挙人名簿 | ■選挙人名簿抄本の閲覧制度見直し(2006年11月) 調査に関しては「統計調査・世論調査・学術研究等の調査研究のうち、政治・選挙に関するものの実施目的での閲覧」以外は認められなくなった。また、閲覧した者の氏名や利用目的の公表、第三者提供の禁止や罰則規定の導入等、全体的に取り扱いが厳格化された。 ※2005年4月の個人情報保護法施行にあわせた公職選挙法改正によるもの。 |
| 電話帳 | ■携帯電話の急速な普及による固定電話契約率の低下 ■電話帳掲載率の大幅低下 |
■非確率的抽出手法に基づく定量調査の台頭
上記のような流れから、それまで標本抽出枠に利用されてきたリストに、マーケティング・リサーチ目的でアクセスすることが不可能になりました。そこで、エリア・サンプリングと呼ばれる住宅地図などを用いて調査対象となる世帯を抽出し、調査員が訪問して調査対象者を選出する非確率的な手法で行うようになりましたが、近年オートロック付きマンションの居住者が増えたり、日中家を空けている共働き世帯が増加したりして訪問面接調査自体も難しくなっています。そうした中、インターネットの一般世帯への急激な普及を背景に、エリア・サンプリングに代わってオンラインアクセスパネルと呼ばれる標本抽出が行われるようになり、現在のマーケティング・リサーチにおける定量調査の対象者抽出の主な手法になっています(※6)。
(※6)データコレクション方法の変化については、以下でも解説をしているので参照してください。
https://www.gmo.jp/report/marketing/27/index.php
■オンラインアクセスパネル
インターネットが一般世帯に普及を開始した1990年代半ばから、いわゆるインターネットを利用した定量アンケート調査は実施されてきました。初期のものは古くから実施されてきた郵送調査をメールに置き換えただけのものでした。
しかし、ウェブ環境が発展してくると、テキストをメールでやり取りするだけの実査方式は姿を消し、電子調査票を用いた自記式調査が一般的となりました。この方式は現在も引き継がれ、調査対象者がインターネットを通じてブラウザで指定URLにアクセスし、回答するとシステムがリアルタイムで自動処理を行う仕組みが構築されています。これによって、これまで人手で行ってきたパンチング(※7)作業が不要になるなど合理化も促進されることになりました。
標本抽出法も大きく変化しました。従来は名簿や電話帳から標本の抽出作業を行っていたのが、インターネット上の広告を用いて自発的に調査に参加しようとする人々の集団である調査パネルを構築して、そこから標本を抽出するようになりました。この調査パネルのことをオンラインアクセスパネルと呼んでいます。
この手法の課題として、そもそも母集団をはじめ母集団を構成する全標本のリスト(標本抽出枠)が設定されていないため、どのような母集団が何を代表する標本なのかを説明できないということがあります。
2000年代までは、こうした非確率的手法であることのデメリットがマーケティング・リサーチ業界から指摘されてきました。しかし、他に適当な標本抽出手法もなく、著しいコストおよび納期圧縮が可能となるメリットが標本抽出に関するデメリットを上回ると考えられるようになり、次第に受け入れられてきました。現在では、非確率的手法であることを前提に、結果から何をどこまで説明できるデータなのか、ということに留意しつつ、コストおよび納期圧縮のメリットを受け入れるという考え方が主流になっています。
(※7)インターネットを使わないオフライン定量調査の場合、調査票が紙であることがほとんどであり、データのクリーニングや集計を行う以前に、パソコン上で入力して電子データにする必要がありました。この入力作業をパンチングといい、穴の開いたパンチカードを用いて集計を行った初期の集計マシンに由来します。
■リバーサンプリング
2000年代に入って一般化したオンラインアクセスパネルであるが、2000年代後半には以下の問題に悩まされるようになり、現在過渡期を迎えていると言えます。
一点が、オンラインアクセスパネルへのアクセス低下、標本回収率低下の問題で、米国では2000年代後半からその傾向が顕著になってきました。
これは、
・当初は面白く斬新な体験であったオンラインでのアンケートに回答する行動が、Web環境の一般化に伴って陳腐化し、面白みを失ってきたこと。
・インターネットを通じたニュース、ゲーム、SNSといった多くのコンテンツが登場して、アクティビティとしての魅力が失われたこと。
・競合企業が増加した結果、業界がレッドオーシャン化し、単価が切り下げられたため調査対象者への回答に対する協力報酬が、初期と比較して非常に安価になってしまったこと。
などが、大きな影響として考えられます。
二点目がパネル内に存在する回答慣れした登録者の問題です。
彼らは
・事実と異なる回答で、スクリーナー(調査対象者条件)を通過しようとする(=虚偽回答の割合が高まる)。
・短時間で回答を終了させるため、よく考えずに回答をする。
といった影響をオンラインアクセスパネルにもたらすこととなりました。
このような回答慣れしたパネル登録者をオンラインパネルから排除するため、ストレートライナー(※8)の検出、トラップ設問の混入、回答時間が極端に短い回答者(スピーダー)の検出など、さまざまな対処法が実践されてきましたが、すべてを排除する方法がない状態が現在でも続いています。
上記の問題をクリアするため、2000年代後半に、米国の調査会社DMS Insights社はリバーサンプリング法という新たな標本抽出手法を提案しました。これは、非常に多くの人が閲覧するポータルサイトなどに調査回答を依頼するバナーを配置するもので、日ごろから定量調査に回答していないフレッシュサンプルを捕まえられるところに大きな意味があります。オンラインアクセスパネルが、釣堀から魚を釣り上げる状況と似ていることを比較して、川を自由に泳いでいる(囲い込まれていない)魚を釣り上げる状況に近いことから、「リバーサンプリング」と称されています。
(※8)マトリクス設問等で同じ選択肢がずっと選択された状態。何も考えずに下に選択肢をクリックするような行動を検出する。
今回のレポートを集約すると次の3点になります。
1.定量調査では、標本抽出における代表性の概念が重要とされている。統計的な手続きを踏まずに実施した抽出では無視できない誤差が生じ、甚だしい場合は、調査の結果そのものが信頼性のないものになってしまう可能性が高い。
2.わが国では、無作為抽出をする際の標本抽出枠として住民基本台帳などのリストが長く利用されてきたが、個人情報保護が重視され始めた1990年代頃からそれは困難になり、現在ではほぼアクセス不可能である。
3.現在では、マーケティング・リサーチの定量調査は、非確率的な標本抽出であるオンラインアクセスパネルを用いて実施されるのが一般的である。しかし、回収率の低下、回答慣れしたパネル登録者の問題があり、フレッシュサンプル取得を目的とした新たな抽出手法の併用が提唱されるようになっている。
次回は、新たな標本抽出手法であるリバーサンプリングなどについて、その詳細と活用の具体例を紹介します。
「リバーサンプリング」についての詳細問合せは以下まで。
GMOリサーチ株式会社 国内事業本部マーケティング部 担当水原
Tel.03-5962-0037
[email protected]

GMOリサーチ
GMOリサーチ株式会社
GMOリサーチは、先進的なネットリサーチで日本とアジアのマーケティングプロセスに新しい価値を提供する会社です。 自社メディア「infoQ」を含むアジアの13ヶ国・地域を繋いだアジア最大級のクラウド型消費者パネル「ASIA Cloud Panel」を保有。 調査会社・シンクタンク・コンサルティング企業など調査のプロに向け、ネットを活用した調査・集計・分析サービスと調査サンプルを柔軟に提供しています。

